主要任务
Proxy web server是csapp第十二章的实验,写一个能缓存的并发的代理服务器。 –> 完成的代码
–> 题目要求
主要分为三个要求:
- Proxy:实现代理功能,接收客户端发送的http请求(只能实现GET方法),转发到目标服务器,从目标服务器获得响应,返回给客户端。
- Concurrent: 实现并发功能,能同时接收多个客户端的请求,并转发到目标服务器。题目中明确提示最好使用线程实现。
- Cache: 缓存访问过的资源。
代理(Proxy)
代理相当于在客户端和服务器端加了一个中间层。对于客户端来说,代理服务器是服务端;对于目标服务器来说,代理服务器是客户端。说来说去,还是服务器-客户端模型。
实现一个代理服务器,接收HTTP/1.0请求,只能实现GET。
原理很简单:
- 代理服务器监听从某一个指定端口进来的所有的请求。
- 代理服务器接收到一个来自客户端的请求,调用
accept函数,将获取的客户端socket信息传入,返回一个已经连接文件描述符connfd,这个描述符利用unix I/O函数与客户端进行通信。 - 从文件描述符
connfd中获取并解析客户端的请求,并获取目标服务器主机名和端口等信息。 - 调用
open_client函数,建立起与目标服务器的请求,返回已连接的文件描述符proxy_fd - 将解析过的HTTP请求写入
proxy_fd,题目规定http请求的某些header必须加上:Host,User_agent,Connection: close,Proxy-Connection: close。 转发请求。- HTTP/1.1 里默认将
connection定义为keep-alive,也就是一条 TCP 连接可以处理多个请求,不用每次都要重新建立 TCP 连接。但是这个proxy 还无法提供这样的功能。
- HTTP/1.1 里默认将
- 获取目标服务器的响应。
- 从
proxy_fd中“取出”目标服务器的响应,写入connfd(返回给客户端)
要注意的点:
- 利用
./port-for-user.pl申请端口,避免使用了已经被占用的端口。申请的总是偶数,所以如果需要一个额外的端口,直接在端口号 +1 即可。 - http请求每行以
\r\n结束,以一个空行\r\n结尾。 (这很坑,一定要加上) - 主机和端口号,需要通过解析http请求的第一行获得,类似于:
GET http:www.example.com/index.html HTTP/1.1在这里,我判断了http和https的区别,如果没有指定端口号的话,分别使用80和443作为端口。要注意的是,这里的解析URL只是简单的解析,只能分离出主机名,文件路径,文件名,端口号,复杂的URL(如含有URL参数的URL)不需要考虑。(实际上,也很难解析出来)。
并发(Concurrent)
首先说说并发编程的实现形式:
进程, 每个逻辑控制流都是一个进程,进程由内核调度(我的理解,内核调度的意思是不用自己写在各个逻辑流中的转化,不用自己调度),每个进程都有虚拟内存空间,要显式地调用进程间通信才能和其他进程通信。多个进程共享状态信息(比如文件表),但是不共享用户地址空间。用多个进程来实现并发。I/0 多路复用,事件驱动,程序在一个进程中显式地调用各自的逻辑流,共用虚拟内存空间。每个逻辑流被模型化为状态机。状态机被抽象为–状态,输入事件和转移:- 状态:当前文件描述符的状态
- 输入事件:文件描述符准备好可以做某件事(如:可读)。
- 转移:转移是将输入事件和状态映射到转移。该文件描述符的输入事件完成–> 进入到准备状态 –> 准备好 –> 开始下一次输入事件 (所以这是一个自循环)
下图是一个状态机: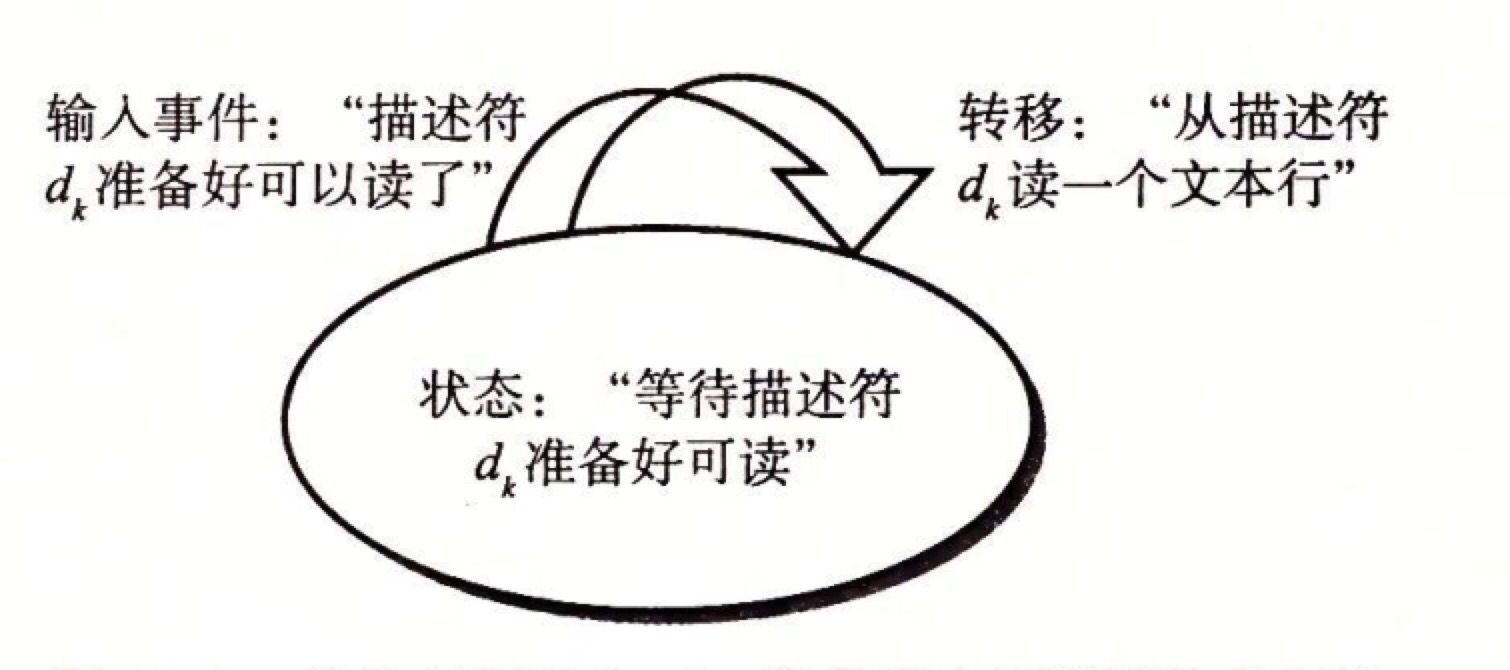
- 使用
select函数:等待一组文件描述符中的一个准备好可读,就返回,从这个文件描述符中执行读操作。select函数是阻塞的,所以select函数阻塞的时候,内核挂起该进程,知道准备好可读,挂起的时候,CPU就可以执行其他,以此实现并发。
我的理解:将一堆文件描述符放到用户池中,将这些文件描述符(其实就是一些读写的逻辑流)模型化为状态机,一直在循环,使用select函数,从这些状态机中选出准备好状态的的逻辑流对应的文件描述符(如果有的话,select函数就会返回),select函数返回后,就可以对这些准备好的文件描述符进行读操作。
线程:在一个进程上下文运行逻辑流,像进程一样由内核调度,像I/O多路复用一样共享虚拟内存空间。由主线程创建对等线程(其他线程),从创建开始,这两个线程并发的运行,如果某个线程进行read,sleep等耗时操作,会切换到对等线程(上下文切换,但是线程的上下文比进程上下文小的多,因为共享虚拟内存空间,很多东西不用写入上下文),对等线程之间能共享数据。- 与进程不同的是,主线程和对等线程不是按照严格的父子层次来组织的(他们之间不是父子关系),主线程和其他线程的区别是,主线程是进程中的第一个线程。一个线程可以杀死它的任何对等线程,或等待它的任何线程终止。
这里利用线程实现。基本思想就是为每一个新的客户端创建一个新线程,这种方法的缺点是:消耗的资源代价太大。
所以,我利用了书上的生产者-消费者模型,实现了预线程化。
原理很简单:
- 服务器由一个主线程和一组工作线程构成。
- 主线程不断的接收客户端的请求,并将得到的已连接的文件描述符放入一个缓冲区。
- 每一个工作者线程不断地从共享缓冲区中取出文件描述符,为客户端服务,然后等待下一个文件描述符。
何为生产者和消费者?
生产者线程和消费者线程共享同一片缓冲区。
- 生产者线程不断地产生新的项目,放入缓冲区(涉及到缓冲区的写入)
- 消费者线程不断地从缓冲区取出项目(涉及到缓冲区的读出),然后消费(使用)他们。
从中,可是看出,放入(写入)缓冲区和取出(读出)缓冲区都涉及到共享变量的读写,所以必须保证,最多同时只有一个线程能读写(取出和放入)缓冲区(需要对相应变量加锁和解锁)但只有这样是不够的,如果,缓冲区是满的,生产者需要等待缓冲区有
空位了再写入,同理,如果缓冲区是空的,消费者需要等到缓冲区有可用项目在取出。
加锁函数: void P(sem_t *sem) ;
解锁函数: void V(sem_t *sem) ;
缓冲区结构:
mutex,slots,items是每次操作需要加锁的共享变量。保证了每次最多只有一个线程对缓冲区进行插入或取出操作。
需要注意:
- 最好在线程一开始执行
pthread_detach(pthread_self()),使调用的线程是可分离的,一个分离的线程不能被其他线程杀死,它的内存资源在它终止时有系统自动释放。这样就不用自己负责清理线程。 - 也可以不用预线程化,直接给每一个客户端一个请求创建一个新线程,只不过消耗略大。
缓存(Cache)
题目设定了缓存大小限制:MAX_CACHE_SIZE = 1 MiB,只缓存 web 对象,其他如 metadata不需缓存,单个文件大小限制 :MAX_OBJECT_SIZE = 100 KiB。
使用LRU,进行缓存。
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
使用双向链表才存储和连接一个个缓存单元,结构如下:
具体实现如下:
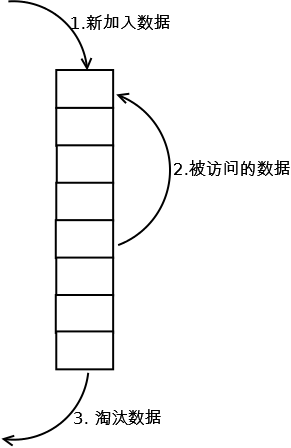
- 新数据插入到链表头部。
- 每某块缓存数据被访问,则将这块数据移到链表头部。
- 当链表满的时候,将链表尾部的数据丢弃。
具体过程:
- 对于每一个客户端的请求,都用这个请求对应的请求行(类似于
GET http:www.example.com/index.html HTTP/1.1) 都需要遍历链表。- 找到请求行相同的数据块(如果能找到的话),然后需要将数据移到头部,并直接将这个结点中储存的资源返回。(只涉及到读)
- 如果找不到,说明之前没有请求过这个资源,或者太长时间没有请求这个资源导致缓存被删除,就需要向目标服务器请求这个资源,返回给客户端,并将这个资源存入结点,再将这个结点查到链表的开头。(涉及到读和写)
需要注意的是,如果这个过程中链表的总量超过了MAX_CACHE_SIZE,就删除链表的最后一个元素,直到小于MAX_CACHE_SIZE.
对于共享链表的访问,使用书上的读者-写者模型。
简单来说,对于一个共享资源,有些线程只读对象(读者),有些线程只写对象(写者),最多同时只有一个写者访问共享资源,但同时可以有多个读者访问共享资源。
意思就是:
- 遍历链表是可以多个线程同时进行(读者),此时无需加锁。
- 插入结点或删除结点(写者)是最多只能由一个线程进行操作,需要加锁。
这样,就把缓存也做好了。
最后
这个lab做了蛮久,完成之后很爽。CSAPP是本神书,从中学到很多,希望一直坚持下去。