机器语言–>汇编语言–>高级语言。
C语言是一门编译型的,面向过程的高级语言,相应的python是一门解释型的,面向对象的高级语言。
计算机是不能够识别高级语言的,所以运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行。
编写C语言的基本步骤
1) 编辑程序。 此时的程序称为源程序,C语言源程序以.c 或.cpp 为后缀。
2) 编译程序。 将源程序翻译成二进程代码的过程,检查错误,翻译成目标文件,.obj。 (#define 定义的宏是在编译的时候被替换)
宏定义:一个标识符来表示一个字符串,有参数的和无参数的。
|
|
3) 链接程序。 将目标程序和系统提供的标准库函数“合成”在一起,生成可执行文件。 a.out或.exe,Linux中,使用gcc或g++,获得可执行文件.out
4) 运行程序。
指针
1) 地址:内存区的每一个字节有一个编号,这就是地址。
2) 指针:将地址形象化的称为“指针”。意思就是通过她能找到以他为地址的内存单元。 在使用一个指针时,一个程序既可以直接使用这个指针所存储的内存地址,又可以使用这个地址里存储的函数值。
两个运算符需牢记:
(1)&:取地址运算符。
(2)*:指针运算符(或称“间接访问”运算符),
指针和指针变量是不同的两个概念:指针是一个地址,而指针变量是存放地址的变量。
地址传递和值传递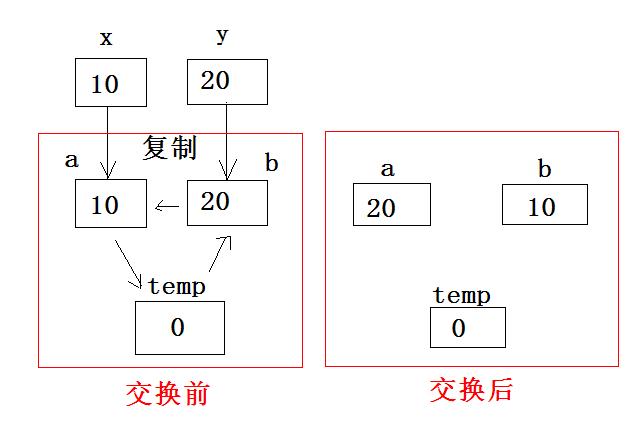
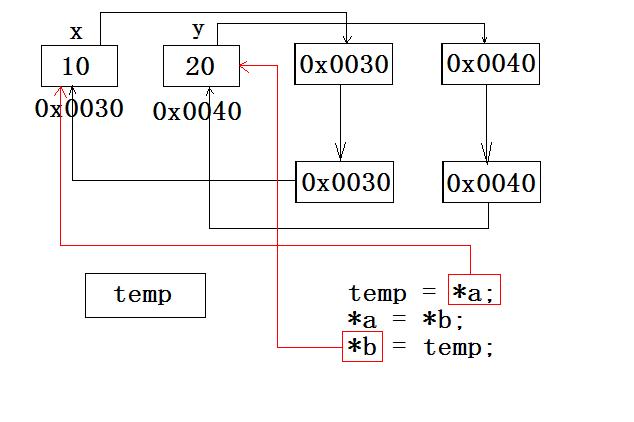
野指针
产生原因 : 指针指向了已经被释放的内存区域
避免野指针三部曲:
1)定义指针时,把指针变量赋值为NULL
2)释放内存时,检查指针变量是否为NULL
3)释放内存后,把指针变量赋值为NULL
segement fault
段错误是指访问的内存超出了系统给这个程序所设定的内存空间,例如访问了不存在的内存地址、访问了系统保护的内存地址、访问了只读的内存地址等等情况。
溢出
1) 数组溢出,0~n-1 ,非法访问时,造成数组溢出
2) 数溢出 数的值超过了他的类型的表示范围。
2147483647 ? or -2147483648
3) 缓冲区溢出
序在运行过程中,为了临时存取数据的需要,一般都要分配一些内存空间,通常称这些空间为缓冲区。如果向缓冲区写入超过其本身长度的数据,以致于缓冲区无法容纳,就会造成缓冲区以外的存储单元被改写,这种现象就被称为缓冲区溢出。
4) 栈溢出 系统的内核栈大小为一个可以设置的定值。一般内核栈的大小为4KB或8KB。因此由于程序的局部变量都分配在栈上,在写程序时模块的局部变量大小之和不应该超过这个栈的大小,否则就会发生栈溢出。
或者递归层数过多。
5) 指针溢出
指针的溢出可以理解为指针的错误运算,而指向了不该指向的地址。这个地址可能是NULL空间,可能是内核空间,也可能是无效的内存空间。
变量的存储类型
变量的存储方式:
1) 静态存储 : 在变量定义时就分定存储单元并一直保持不变,直至整个程序结束。 如全局变量。
2) 动态存储 : 动态存储变量是在程序执行过程中,使用它时才分配存储单元, 使用完毕立即释放。 典型的例子是函数的形参。
C语言总共有四种存储类型的变量,分别为自动变量(auto)、静态变量(static)、外部变量(extern)以及寄存器变量(register)。
1) 自动变量:局部变量,auto是默认的存储类型,不需要显示的指定。生存期在一对{}内。(与它对应的是全局变量) 。 是动态存储的。只有调用定义这个变量的函数时,才为它分配内存空间,
2) 寄存器变量:一般经常被使用的的变量(如某一变量需要计算几千次)可以设置成寄存器变量,register变量会被存储在寄存器中,计算速度远快于存在内存中的非register变量。 是动态存储的。
3) 静态变量:在变量前加上static关键字的变量。 是静态存储的。
4) 外部变量:一般用作全局变量作用域的扩展(还有定义外部函数的时候前面也可以有一个extern关键字)。 是静态存储的。
栈区,堆区,全局区,代码区
C语言程序中, 代码在内存中进行执行的时候,我们粗略的将程序所占用的内存分为四个区域—-栈区,堆区,全局区,代码区.
1) 栈区:
编译器自动分配释放, 存放函数的参数值,局部变量等。
2) 堆区:
一般由程序员分配释放(动态内存申请与释放),若程序员不释放,程序结束时可能由操作系统回收
3) 全局区
全局变量和静态变量存放在此. 里面细分有一个常量区, 字符串常量和其他常量也存放在此.常量在其中只有一份拷贝,不会出现相同的变量和常量的不同拷贝。该区域是在程序结束后由操作系统释放.
4) 程序代码区
这个区域存放函数体的二进制代码.也是由操作系统进行管理的.
C语言程序中,根据是局部变量,全局变量, 常量还是通过malloc等类似的函数分配内存空间, 把他们放到对应的内存区中.这样就赋予了这些变量或常量不同的生命周期, 不同的释放方式. 根据程序的需要,在编码过程中,声明不同的变量类型, 使他们有不同的声明长度, 不同的释放方式,给我们更大的灵活编程。