一些常用的Docker命令
docker help +[command]
这个命令可以查看所有docker的命令和它的参数,非常实用
关于容器管理的命令
docker run
docker run [OPTIONS] IMAGE [COMMAND] [ARG...]
这个命令会启动一个docker容器(Run a command in a new container) ,如果本地没有这个镜像,会从Dockerhub(默认)上下载运行。有几个option比较常用:--name <name>给容器命名--env <key>=<value> 或-e <key>=<value> 设置环境变量--volume <path> 或 -v <path> 将主机该目录下的文件挂载到容器中--volume <h-path>:<c-path> 或 -v <h-path>:<c-path> 容器上挂载指定的主机目录--rm 关闭容器之后自动清除容器--volumes-from <another-container> 访问另一个容器的volume(数据共享)--iteractive或-i 显示(获得容器中的输出)--tty或-t允许向容器内部发送信号(经常和-i一起使用,来与容器交互)--detach或-d在后台运行-p <port>:<port> 将主机的端口映射到容器的端口--link与另外一个容器连接
其中--restart是容器的重启机制,有4中类型
1.no ,当容器关闭时,从不自动重启,这是默认状态。
2.on-failure[:max-retries],只有在容器以非零状态关闭时重启,可以设置最大尝试重启的次数
3.always ,无论任何情况都会重启,而且当docker daemon启动时,容器也会自动启动
4.unless-stopped,无论容器以什么状态停止都会重启,但是docker daemon启动,如果容器事先是停止状态,就不会重启(这里书上和文档上讲的不一样,以文档为准)
docker run的option非常多,因为它运行一个容器的同时,可以添加参数修改build镜像时的默认设置,使用时,有需要用docker help查询
docker create
docker create [OPTIONS] IMAGE [COMMAND] [ARG...]
创建容器(Create a new container),这个命令和 docker run很像,但是不启动容器,很多option也类似。但是docker create如果没有直接命名容器的话,会随机产生一个形容词+名词的容器名
docker ps
docker ps [OPTIONS]
列出容器(List containers),默认只列出启动的容器,常用option:-a 列出所用容器-q 或 --quiet只列出容器ID-s 或 --size列出容器大小docker ps最常用来显示正在运行的容器
docker exec
docker exec [OPTIONS] CONTAINER COMMAND [ARG...]
在容器中运行命令(Run a command in a running container),常用形式:docker exec -it <container> /bin/bash 进入容器
docker kill 与 docker stop
docker kill [OPTIONS] CONTAINER [CONTAINER...]
docker stop [OPTIONS] CONTAINER [CONTAINER...]
docker kill 和docker stop都是关闭一个容器,但它们是有区别的:
文档上是这样说的:docker kill: Kill a running container using SIGKILL or a specified signaldocker stop: Stop a running container by sending SIGTERM and then SIGKILL after a grace period
所以:docker kill kill直接执行kill -9(直接发送SIGKILL),强行终止docker stop 发一个SIGTERM,让容器自己停。容器进程规定之间内不停,那么再调kill -9
docker rm
docker rm [OPTIONS] CONTAINER [CONTAINER...]
移除一个已经停止的容器(Remove one or more containers) 常用option-f 或 --force 强制删除 (运行中的容器,发送SIGKILL)-link 或 --link 同时删除link-volume 或-v 同时删除volume
docker logs
docker logs [OPTIONS] CONTAINER
查看容器日志(Fetch the logs of a container) ,常用 :-f 或 -follow 持续展示日志,CTRL+C 停止
其实日志会随着容器的存在一直写入,docker logs一直变长,所以可以把docker logs挂载在本机
docker inspect
docker inspect [OPTIONS] NAME|ID [NAME|ID...]
显示容器的底层信息(Return low-level information on Docker objects)默认为json格式返回数据 , docker inspect显示的信息有很多,一般和grep配合使用,找出所需的信息,如docker inspect <container> | grep IPAddress ,也可以使用-f或--format定义返回的格式
docker export 和 docker import
docker export [OPTIONS] IMAGE [IMAGE...]
持久化容器(Export a container’s filesystem as a tar archive),一般这样调用:docker export <container> > <filename> 或 docker export -o <filename> <containr> 将容器导出到指定文件
docker import [OPTIONS] file|URL|- [REPOSITORY[:TAG]]
从容器快照文件中再导入为镜像(Import the contents from a tarball to create a filesystem image) , 一般这样调用:cat filename.tgz | docker import - image:tag 从本地文件导出
也可以通过指定 URL 或者某个目录来导入.
关于镜像管理的命令
docker images
docker images [OPTIONS] [REPOSITORY[:TAG]]
列出镜像(List images),默认的 docker images 列表中只会显示顶层镜像,常用:-a 显示所有镜像-f或 --filter 列出所有符合条件的镜像(删选)
可以看到列出镜像中,有一些镜像的仓库名和标签均为
- 新旧镜像同名,旧镜像名称被取消,从而出现仓库名、标签均为
的情况, docker pull和build build都有可能产生这种镜像.这些镜像可以删除,使用docker images -f dangling=true可以列出这种镜像,使用docker rmi $(docker images -q -f dangling=true)删除镜像 - 在构建镜像过程中产生的中间镜像,默认的
docker images中只会显示顶层镜像,如果希望显示包括中间层镜像在内的所有镜像的话,需要加-a参数。这些镜像是其它镜像所依赖的镜像,不能删除。
docker search
docker search [OPTIONS] TERM
在Dokcerhub中寻找镜像(Search the Docker Hub for images),常用 :
--automated , 只找自动build的镜像
--stars或-s,镜像仓库至少要几星
--limit 最大查找数量
docker search非常实用,可以直接在命令行中查找镜像,查看镜像的信息
docker pull
docker pull [OPTIONS] NAME[:TAG|@DIGEST]
从镜像仓库中拉取镜像,(Pull an image or a repository from a registry)不一定是Dockerhub,但是默认为Dokcerhub,可以更换为其它的镜像仓库地址。--all-tags或-a,拉取所有这个仓库里所有标记了的镜像,一般是不需要的,所以在拉取的时候最好写好tag
dokcer build
docker build [OPTIONS] PATH | URL | -
根据Dockerfile创建镜像(Build an image from a Dockerfile)
编写Dockerfile可以使用Dockerhub中的基础镜像,制作自定义的镜像。首先Dockerfile很小(只是一个文本文件),容易传播,可以根据自己的需要定制镜像(比如本机环境不同),但是Dockerfile的编写又是一门学问了2333。
也可以根据GitHub上的Dockerfilebuild镜像,比如:
docker build <仓库地址>#<branch>:<directory>
也可以根据压缩包构建镜像:
docker build http://server/context.tar.gz
一般用-t为构建的镜像添加tag
docker save 和 docker load
docker save [OPTIONS] IMAGE [IMAGE...]
持久化镜像(Save one or more images to a tar archive) 一般这样调用
docker save image:tag > <filename> 或 docker save -o <filename> image:tag 都是把镜像导出到指定文件
docker load [OPTIONS]
导出镜像(Load an image from a tar archive or STDIN)docker load导入镜像存储文件到本地镜像库,docker import导入一个容器快照到本地镜像库。这两者的区别在于容器快照文件将丢弃所有的历史记录和元数据信息(即仅保存容器当时的快照状态),而镜像存储文件将保存完整记录,体积也要大.因此,从容器快照文件导入时可以重新指定标签等元数据信息。
docker rmi
docker rmi [OPTIONS] IMAGE [IMAGE...]
删除镜像(Remove one or more images) 。-f或--force常用于强制删除
Docker底层实现
Docker 底层的核心技术包括 Linux 上的命名空间(Namespaces)、控制组(Control groups)、Union 文件系统(Union file systems)。(不详细介绍,因为不是很了解)
容器的本质是资源隔离,利用的是Linux内核中已有的机制(其实就是新瓶装旧酒)。
传统的虚拟机通过在宿主主机中运行 hypervisor 来模拟一整套完整的硬件环境提供给虚拟机的操作系统。虚拟机系统看到的环境是可限制的,也是彼此隔离的。 这种直接的做法实现了对资源最完整的封装,但很多时候往往意味着系统资源的浪费。
与虚拟机相比,一个基础镜像的下载,能被很多镜像利用,不会有冗余。但虚拟机之间是不能相互利用,也不能利用主机资源,必定会造成浪费。
Container更像一种机制–某些进程共用一个内核和某些运行时环境(例如一些系统命令和系统库),但是彼此却看不到,都以为系统中只有自己的存在。这种机制就是容器(Container),利用命名空间来做权限的隔离控制,利用 cgroups 来做资源分配。
namespace
Linux Namespace是Linux提供的一种内核级别环境隔离的方法。 –>这是文档
有如下种类:
Mount namespaces
UTS namespaces
IPC namespaces
PID namespaces
Network namespaces
User namespaces
通过这些namespace机制解决了环境隔离的问题,每个容器都有自己单独的命名空间,运行在其中的应用都像是在独立的操作系统中运行一样。命名空间保证了容器之间彼此互不影响。
UTS namespaces (UNIX Time-sharing System)
主机名和域名的隔离,这样每个docker容器可以作为网络中的一个节点,而非宿主机上的一个进程。每个镜像都是使用自身提供的服务名来作为镜像的hostname,不会对宿主机产生影响。
IPC namespace (Inter-Process Communication)
进程间通信的隔离,涉及到的IPC资源包括常见的信号量,消息队列和共享内存。申请IPC资源就是申请了一个全局的唯一的32位的ID,所以IPC namespace中实际上包括系统IPC标示和实现POSIX消息队列的文件系统,在同一个IPC namespace下的进程彼此可见,不在同一个IPC namespace下的进程彼此不可见。
在宿主机中用 ipcmk -Q 创建一个消息队列,用 ipcs -q可以看到查看到这个消息队列,但是运行脚本,创建一个新的IPC namespace之后,使用ipcs -q看不到这个消息队列,说明实现了消息队列的隔离。
PID namespace
PID 的隔离,对进程PID进行重新标号,使两个namespace内的进程可以有相同的PID,有以下特点:
1) 每个PID namespace的第一个进程“PID 1”,像传统Linux系统的中的init进程一样有特权,起特殊作用。
2)一个namespace中的进程,不能通过kill或ptrace影响其他父节点或兄弟节点中的进程,因为其他节点的PID在这个namespace中没有意义。
3)在root namespace中可以看见所有的进程,并递归含有所有子节点的进程。
使用 ehco $$查看当前进程的进程号,可以看到运行脚本之后,PID是不同的。但是使用ps或top等命令还是能看见所有父进程的PID,是因为与PID直接相关的/proc系统还是挂载在原/proc中,(使用mount -t proc proc /proc重新挂载/proc,这样就可以只看见这个PID namespace的PID),ps和top调用的是在真实的系统下的/proc文件,所以看见的还是原来的进程。所以PID namespace还是需要一些额外的工作才能确保进程顺利进行。
1) PID namespace中的init进程
PID为1的进程是init,它是所有进程的父进程,维护一张进程表,不断的查看进程的状态。一旦某个进程因为它的父进程错误变成了“孤儿”进程,init进程就会收养这个子进程,并进行资源回收,结束进程。所以,要实现容器的话,需要实现类似init进程的功能,维护后继启动进程的运行状态。–在docker容器中运行多个进程,最先启动的进程应该有资源监控和回收的管理功能,如bash。当系统中存在树状嵌套的PID namespace时,如果某个子进程变成孤儿进程,该PID namespace的init进程就负责收养改子进程。
2)init进程与信号屏蔽
信号屏蔽功能,如果一个PID namespace中的init进程没有编写处理某个信号的逻辑,那么这个namespace中的其他进程(即使是超级用户权限)给init进程发送这个信号时,init会屏蔽这个信号,主要是防止init进程被误杀。
父节点PID namespace给其子节点发送的信号(如果没有编写处理这个信号的逻辑),子节点的init进程也会忽略这个信号,但如果这个信号是SIGKILL(销毁进程)或SIGSTOP(结束进程),子节点的init进程就会强制执行,结束子节点中的相应进程。可以对init进程进行设置,选择需要被捕获的信号。
mount namespaces
挂载的隔离,进程创建新的mount namespace时,会把当前文件结构复制给新的namespace,新的namespace中的所有mount操作都只影响自身的文件系统,不会对外界产生影响。
挂载分为以下几种:
1)共享挂载(share)传播事件的挂载对象
2)从属挂载(slave)接收传播事件的挂载对象
3) 共享/从属挂载(share/slave)兼有前两者
4)私有挂载(private)不传播也不接收传播事件的挂载对象
5)不可绑定挂载(unbindable)与私有挂载相似,且不允许执行绑定挂载
如图: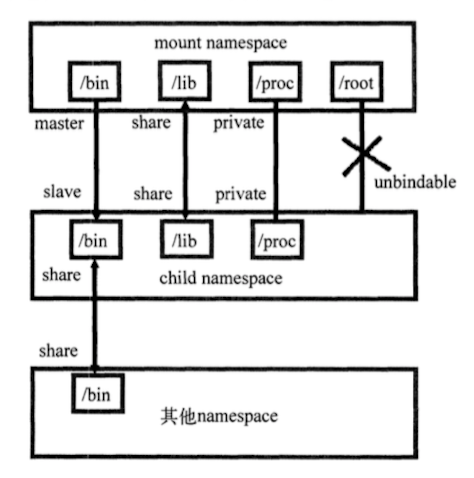
默认情况下,所有挂载都是私有的。mount namespace生效之后,子进程中所有的挂载和卸载操作都只在这个mount namespace中进行。
network namespace
network namespace主要用于网路资源的隔离,包括网络设备,IPv4盒IPv6协议栈,IP路由表,防火墙,/proc/net目录,套接字(socket)。
network namespace是把网络独立出来,给外部用户一个透明的感觉,仿佛在与一个独立的网络实体进行通信。为了实现这个目的,容器的做法是创建一个新的veth path,一段放置新的network namespace,通常命名为eth0,一段放置原先的network namespace中链接的网络设备,再通过多个设备接入网桥或进行路由转发,来实现通信目的。
user namespace
user namespace隔离了安全相关的标识符,和属性,包括用户ID,用户组ID,root目录,key(密钥)。
一个普通用户的进程通过clone()创建的新的user namespace中,可以拥有不同的用户和用户组,这意味着一个没有特权的普通用户,在它创建的容器进程中,却是拥有全部权限的超级用户。(拥有所有权限的超级用户的user ID是0)
user namespace被创建之后,第一个进程被赋予了所有权限,这样该init进程就可以完成所有必要的初始化操作。 新的namespace中的用户可能在这个namespace中存在,但是在父namespace中没有权限
cgroup
Linux CGroup全称Linux Control Group, 是Linux内核的一个功能,用来限制,控制与分离一个进程组群的资源(如CPU、内存、磁盘输入输出等)。 namespace解决了环境隔离的问题,cgruop解决资源隔离的问题。
其实我觉得就是通过对共享资源进行隔离、限制分配到容器的资源,比如CPU限制,内存使用限制等。
UnionFS
Union File System联合文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下。
UnionFS是 Docker分层镜像的基础。镜像可以通过分层来进行继承,基于基础镜像,可以制作各种具体的应用镜像。
Docker镜像是由多个文件系统(只读层)叠加而成。启动一个容器的时候,Docker会加载只读镜像层并在其上添加一个读写层。如果运行中的容器修改了现有的一个已经存在的文件,那该文件将会从读写层下面的只读层复制到读写层,该文件的只读版本仍然存在,只是已经被读写层中该文件的副本所隐藏。当删除容器,并通过该镜像重新启动时,之前的更改将会丢失。
–>这是一张图: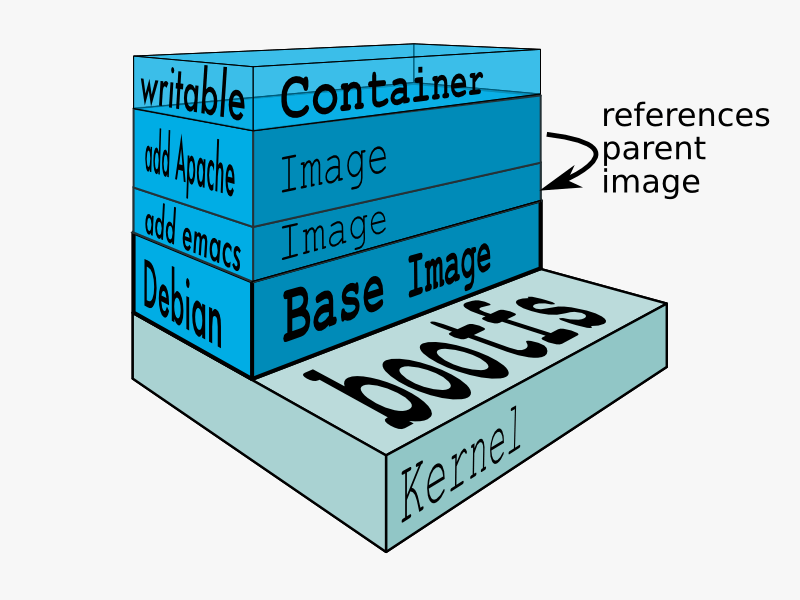
关于volume
volume是为了保存(持久化)数据以及共享容器间的数据。简单来说,volume就是目录或者文件,它可以绕过默认的UnionFS,而以正常的文件或者目录的形式存在于宿主机上。
volume可以将容器以及容器产生的数据分离开来,这样,当你使用docker rm <container>删除容器时,不会影响相关的数据。
volume可以使用以下两种方式创建:
1.在Dockerfile中指定VOLUME /some/dir
2.执行docker run -v /some/dir命令来指定
它们都做了同样的事,在主机上创建一个目录(默认是/var/lib/docker下),将其挂载到容器中的指定目录(如果没有,该目录会自动创建),当该容器被删除时,volume本身不会被影响。
那么,Dockerfile中使用VOLUME指令挂载目录和docker run时通过-v参数指定挂载目录有什么区别?
Dockerfile中使用VOLUME指令挂载目录和docker run时通过-v参数指定挂载目录的区别在于,run的-v可以指定挂载到宿主机的哪个目录,而Dockerfile的VOLUME不能,其挂载目录由docker随机生成。
此外,使用Dockerfile还有一点值得注意:Dockerfile的VOLUME指令后的任何东西都不能改变该Volume,比如:
该Docker file不能按预期那样运行,我们本来希望touch命令在镜像的文件系统上运行,但是实际上它是在一个临时容器的Volume上运行。根据官方文档,Dockerfile生成目标镜像的过程就是不断docker run + docker commit的过程,执行一个指令,docker commit产生临时镜像,docker run产生临时容器.Dockerfile中的每个指令都会产生一个新的容器,也就是说,会创建一个新的volume。
这个Dockerfile中是先指定volume的,所以当执行touch /data/x命令的容器创建时,一个volume先被挂载到/data,然后x才能被写入此volume,而不是实际的容器或镜像的文件系统内。(而我们实际上是想在容器中创建x文件)
所以,Dockerfile中VOLUME指令的位置很关键,因为它在镜像内创建了不可改变的目录。
docker volume
Docker 1.9新增了docker volume命令,这样使用volume就比较方便,文档是这样写的:docker volume create Create a volumedocker volume inspect Display detailed information on one or more volumesdocker volume ls List volumesdocker volume prune Remove all unused volumesdocker volume rm Remove one or more volumes
可是使用这个命令删除无用的volume(volume没有被任何容器挂载) :
docker volume rm $(docker volume ls -qf dangling=true)
总之,通过volume,可以绕过docker的Union File System,从而直接对宿主机的目录进行直接读写,实现了容器内数据的持久化和共享化。
#s docker deamon和 docker client
docker命令有两种模式deamon模式和client模式,属于docker deamon子命令的属于deamon模式,其余都是client模式。
docker采用传统的client-server模式,用户通过docker client和docker deamon进行沟通,并将请求发送给后者,
docker deamon是docker在后台的守护进程,它负责相应docker client的请求。提供了API server来接收来自docker client的请求,然后根据请求的不同,将请求分发给docker deamon的不同模块来执行相应的工作。
docker client是一个泛称,用来向docker deamon来发起请求,既可以是命令行工具docker,也可以是任何遵循了docker API的客户端(包括C#,java,Go,ruby等)
1) docker client
docker client 会创建一个client实例,来发起向守护进程的请求。流程如下:
- 解析传入参数,并对参数进行配置处理
- 获取与docker deamon通信所需的认证配置信息
- 根据命令业务类型,给docker deamon发送POST,或GET请求。
- 读取来自docker deamon的返回结果。
2)docker deamon
deamon同一个server模块来接收来自client的请求,然后根据请求的类型去具体执行。所以:
- 首先启动接收命令的API server
- 初始化一个deamon对象来处理接收来的请求。
以上,仅仅是对docker client和docker deamon的感性认识,实际情况复杂很多。
总结如下:
1) docker/docker.go是所有命令的起始,它创建出来的client和/api/client/cli.go对应
2) api/目录下是所有的有关于client发送请求和server相应请求的文件
3) api/server/xxx.go文件中定义的CmdXXX函数,其中调用cli/client.xxx函数指明了该命令如何发起请求。
4) api/server/router中按照不同请求的具体类型定义了相应请求的方法。
5) 每个请求的处理函数都在deamon/中有一个xxx.go定义了相应的处理函数。
6) deamon对象是由deamon/deamon.go创建的。