从在浏览器上输入网址,到屏幕上出现网页的内容,这期间发生了什么呢??
浏览器生成消息
解析URL
先解释URL和URI,URN:
URI: uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。
URL: uniform resource locator, 统一资源定位符,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何定位这个资源。
URN: uniform resource name, 统一资源命名副,是通过名字来标识资源。
URL是URI的子集,以人为例,每个人的身份证号码是独一无二的,能唯一的确定一个人,就是这个人的URI,比如这个人是中国/湖北省/武汉市/XX大学/东区X栋/XXX寝室/4号床位/XXX/ ,以这种定位的方式也能唯一确定一个人,这是URL。
所以不论是用定位的方式还是用编号的方式,我们都可以唯一确定一个人,都是URI的一种实现,而URL就是用定位的方式实现的URI。
URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。URL和URN都是一种URI。
在在浏览器中输入一个URL(统一资源定位符)如 http://www.balabala.com/dir/file.html/ (这个网址不存在,是我随便编的) 浏览器首先要解析URL,各式各样的URL差不多都可以分为这几种元素: 协议,服务器域名,文件目录,文件名。 比如,在这个网址中,http就是协议,// 后面的www.balabala.com表示服务器域名,dir表示文件目录,file.html表示所求文件名。这样就能准确定位一个资源。
有些URL,比如http://www.baidu.com ,可以看到并没有文件目录和文件名,说明它们是可以省略的,省略时,访问的是服务器根目录上事先设置好的默认文件。
URL有不同的写法,但是URL开头的文字一般表示浏览器当前使用的协议(其实叫访问方法更为合适,因为file: 没用使用协议),包括:
通过解析URL之后,浏览器获得了想要获取的服务器名和文件名。
生成HTTP请求消息
以HTTP为例,浏览器将根据规定生成请求消息,消息分为消息头,消息行,消息体。
请求消息的一行是消息头。
方法有GET,POST,PUT,DELETE,HEAD,OPTIONS等,但是一般情况下GET和POST就够用了。GET意为获取服务器端数据,POST意为想服务端发送数据。
URI(Uniform Resource Identifier) 统一资源标识符,一般来说,是一个存放网页数据的文件名(如前文的 /dir/file.html ) 或一个存放CGI程序的文件名(浏览器可以调用该CGI程序)
HTTP版本号现在一般是 1.1
消息头下面是消息行,最有由一个空行结尾。
消息行的消息以键值对的形式规定了许多额外的消息,如日期(Date),客户端支持的数据类型(Content-Type),语言(Accpet-Language) 等
消息行之后就是消息体,包含客户端向服务器端发送的数据,如POST方法中向服务器传输的表单数据。
向DNS服务器查询Web服务器的IP地址
DNS域名解析
浏览器虽然能够生成请求信息,但是不具备发送信息的功能。将信息发送到网络中需要操作系统的帮助。在此之前,还需要根据服务器域名获取服务器的IP地址。
首先了解一下IP地址。
IP地址是一般是一串32位的数字,8比特一位分为4组,表示计算机在网络中的地址,TCP/IP网络是通过IP地址获取通信对象的,如果没有IP地址,就没有办法通信。 像www.baidu.com 这样的不是IP而是域名。相比数字,一串有意义的英文字符更容易记忆,所以,一般访问网站时使用域名。但是如果通过域名来确定通信对象的话,一是,域名没有确定的长度,且域名最一般最短也也有几十字节,这样增加了路由器的负担,降低了网络请求发送和接受的效率。所以,解决方法就是,让人使用域名,再通过域名解析获取相应的IP地址。
前文说到路由器,何为路由器?就像快递传送途中的各个站点,通过这些站点,能将快递送到目的地,将整个快递传输系统连成一个网。
学校和家里的局域网,可以看成一个子网,子网是通过路由器连接起来的,连接了这个子网的计算机,通过这个路由器与外界的网络联系。
通过解析器向DNS服务器发出请求获取IP地址
如何获取域名对映的IP地址呢?
世界上有许多DNS服务器,上面储存的IP地址与域名解析之间的映射关系(这其实是简化的理解,并不是简单的映射关系),要获取IP地址,可以向DNS服务器发起请求查询IP地址。原理很简单,只要向DNS服务器询问www.baidu.com的IP地址就可以了。
向DNS服务器发起请求,这就要求本机上要有DNS客户端相应DNS服务器的相应消息,这个DNS客户端就是解析器,其本质就是一段程序(或说函数),位于Socket库中。Socket库中的函数能让应用程序调用操作系统的网络功能(因为浏览器不能发网络请求,就必须通过操作系统,Socket库中封装的函数,能让浏览器等应用程序调用,实现网络请求)。
假设这是一段浏览器中的代码:
函数gethostbyname就是解析器。程序运行到这里时,原本浏览器中正在运行的代码暂停,调用解析器,控制流程转移到操作系统,解析器生成请求信息,再通过调用操作系统内部的网络控制软件(其实和浏览器一样,解析器本身也不能发送网络请求,必须通过其他函数。其实很多功能的实现都是通过调用现有模块,现有函数,代码复用可以减少工作量,也能时程序更标准化)发送查询IP地址的请求,获取响应,响应中包括所求的IP地址,解析器取出IP地址,将其存入浏览器指定的内存区域,这样就获取了通信对象的IP地址。
DNS服务器大接力
其实有个现实问题,全世界的计算机不计其数,不可能将全世界所有的IP和域名的映射关系存到同一个DNS服务器中。必须通过各个DNS服务器之间的接力配合才能获取查询的IP地址。
域名的层次结构
观察域名 www.baidu.com 发送它被.分隔,具有层次结构。在域名中,越靠右,层次越高,处于同一个层次的个体属于同一个域,可以把每个域看作一个整体。将一个域的信息存入同一个DNS解析器中,于是,DNS服务器也有了像域名一样的层次结构,每一个域的信息都放在相应层级的DNS服务器中,上一级DNS服务器中存放着下一级DNS解析器的信息,一级一级顺藤摸瓜,可以获取最终的IP地址。
根域
根域就是最顶级的域,根域就是一个点(.) 。 其中存着 com , jp 等次级域的信息。分配给根域的DNS服务器的IP地址在全世界只有13个,因此,全世界所有的DNS服务器中,都存着这13个服务器的信息,因此,访问任何一个DNS服务器,都可以获取根域的信息,再一级一级往下找。
具体流程
以 www.balabala.hahaha.com为例。
如此,浏览器获得了通信对象的IP地址,存储在对应的内存地址。
socket:连接,通信与断开
什么是socket?
socket是什么?这个问题困扰了我很久。socket的中文翻译是套接字,emmmmmm非常难以描述。就说一下自己的理解吧。
Unix/Linux里有个思想是“一切皆文件”,可以把socket看成一个文件,它可以打开(connect),读(read),写(write),关闭(close)。但是socket是一个特殊的文件,特殊之处在于socket中的信息是可以从它连接的两端读出,写入,实现通信的功能。
socket”打开—读/写—关闭”模式的实现,以使用TCP协议通讯的socket为例,其交互流程大概是这样子: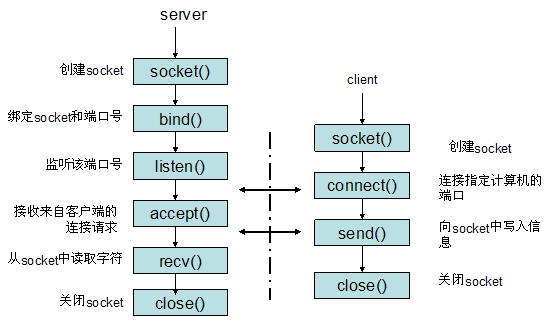
socket其实没有实体,只是一个概念,如果一定要说实体,内存中有一块区域,储存着控制通信操作的信息,如通信对象的IP地址,端口号,通信操作的进行状态等信息,这些内存区域就是socket的实体。通过对象的IP地址和端口号,可以确定通信对象,在通信的过程中,通信操作的进行状态也被储存下来(如通信对象是否收到响应),用于后续的通信。
调用socket的操作
Socket库中有很多操作socket的函数,在应用程序中调用,创建socket,连接,通信,断开,都是在应用程序中调用的。
假设这是一段浏览器中的代码:
这段伪代码和上面那段很像,但是把<发送http请求> 换成了socket的一系列操作。其实<发送http请求>是一个笼统的说法,它的实现需要很多“精细”的操作,socket的创建,连接,通信,关闭,就是其中之一(或说是实现<发送http请求>的方法)。
图中浏览器调用socket方法时,声明遵守TCP协议,接下来的说明时关于TCP的。
创建socket
socket的实体是一段内存空间,创建socket就是操作系统为其分配所需的内存空间,初始化其状态信息(写入初始状态,通信对象的IP地址和端口号),返回socket的描述符,这个描述符相当于socket的编号,后续可以使用描述符来确定相应的socket,获取通信所用的信息。
连接服务器
其实在服务器端也创建了监听socket(该socket的IP地址和端口号就是客户端socket中储存的IP地址和端口号),用于等待客户端socket的连接请求(监听socket中没有通信对象的IP地址和端口号)。当客户端发起连接请求时,就会告知服务器端客户端socket的IP地址和端口号。
实际上,“连接”服务器的说法不是很准确,因为并没有真正的像管道一样的东西连接了客户端和服务器端,而它们的“连接”状态以通信控制信息的形式储存在各自的socket和头部(主要是TCP头部)中。在这个“连接”的过程中,客户端向服务器端传达了通信请求,双方交换了通信所需的控制信息(比如,监听socket创建时,并没有通信对象的IP地址和端口号),创建了临时收发数据所需的内存空间(缓冲区),所以,与其说是“连接”服务器,“准备”更为恰当。
IP模块与以太网包的收发
包的概念
关于通信过程中的控制信息,大概包括两方面。
一,socket中储存的信息(通信对象的IP地址和端口号,通信状态等)
二,头部中保存的信息。有些信息不仅在客户端和服务器端连接时需要,在整个通信过程都需要,所以将信息储存在头部。这里的头部包括TCP头部,IP头部,以太网头部。
其结构如图:
可以看出,原本的应用数据,由TCP头部包裹,封装成TCP包,TCP包由IP头部包装,封装成IP包,IP包由以太网头部包装,封装成最后传输的数据包。当接收方获取到数据包之后,再一层一层打开。
这里强调一点,在TCP层面,TCP头部包装的用户数据(也就是HTML等应用层数据)其实只是普通的二进制数据流(虽然HTML可以渲染出页面,但是TCP层只是把它看作普通数据),在IP层层面,整个TCP段(TCP头部和用户数据)是普通的二进制数据流,用IP头部进行包装。以此类推,每一层都将其上一层作为普通数据进行封装。当接受方收到数据时,在一层一层揭开,得到用户数据。
TCP头部中的信息:
关于TCP连接,可见另一篇博客 –> 可靠的TCP。
众所周知,TCP连接三次握手,四次挥手,它的实现也是通过socket实现的,如图:
IP模块
IP模块是数据包传输的“入口”,当应用层数据被加上了TCP头部,TCP模块就会“委托”IP模块“发送”数据包,这个“发送”实际上是由集线器,路由器等网络设备完成的,IP模块的工作是给数据包加上IP头部和以太网头部,所以说IP模块是数据包传输的“入口”。IP模块负责添加这两个头部:
前文说到,IP模块会讲TCP模块的数据(TCP头部和应用层数据)看作一个普通的二进制数据块,不关心TCP头部信息和应用层数据,换言之,IP模块不关心TCP模块的操作,对于包的乱序和丢失也一概不知。总之,IP模块的就是TCP模块委托的数据包打包“发送出去”,或者接收对方的数据包。
IP头部
IP头部中包括很多通信信息,其中最重要的是通信对象的IP地址,这个IP地址是由TCP模块告知的,如果IP地址是错误的,IP模块也不会校验,因为IP模块无法判断包的目的地。通过IP头部的IP地址就可以判断数据包发送到哪里了,但是以太网判断数据包目的地的方式与TCP/IP方式不同,想把数据包发送出去,必须要采取与以太网相匹配的方式,所以就需要以太网头部。
以太网头部
IP模块在生成IP头部之后,会再加上MAC头部,MAC头部就是以太网头部。MAC头部中有发送方和接收方的MAC地址(类似于IP地址,但是MAC地址是48比特)。那么如何获取接受方的MAC地址呢?
在以太网中有一种“广播”的方法–ARP(Address Resolution Protocol,地址解析协议)。ARP就是通过向同一以太网中的其中设备发送包查询MAC地址。相当于,在同一以太网中,利用”广播“对所有设备说:”XXXX这个IP地址是谁?请把你的MAC地址发给我”,其它设备听到“广播”后,会检查这个IP是不是自己的,如果不是,直接忽略,如果符合,就把自己的MAC地址发送给它。这样就获取了MAC地址。
IP地址和MAC地址接力
可以看到IP和地址MAC都是不可或缺的,IP地址确定通信对象,通过IP地址获取通信对象的MAC地址,然后在以太网中通过MAC地址传输数据包。
实际的情况比这个复杂,数据包不可能直接从客户端发送到服务器端,中间经过了很多“驿站”(就像快递一样),这里的“驿站”就是路由器。
路由器和交换机
数据包的传输靠的是路由器和交换机(实际上,家用的路由器已经具有交换机的功能,不存在“纯粹“的路由器和交换机,这里把它们分开是为了说明它们各自的各自的功能) ,这里就简单一下它们工作的大致流程。
路由器是基于IP设计的,交换机是基于以太网设计的。
当一个路由器收到一个包时,从IP路由表中查询下一个路由器的IP地址,通过ARP(需要IP地址)查询下一个路由器的MAC地址,将MAC地址写入MAC头部,交换机通过以太网将这个包发送到下一个路由器,下一个路由器重复操作,直到送达到目的地。
简单的说,(路由器)负责将数据包发送给通信对象这一整体过程,而其中,将数据包传输到下一个路由器是由以太网(交换机)执行的。